

|
|
 Shakespeare im Burgenland
Shakespeare im Burgenland
oder
was hat Hamlet mit der burgenländischen Wirtschaftsförderung zu tun??
.....To be, or not to be- & dieses Zitat kennt jedes Kind. Doch die Stelle im Buch mit einem Griff zu finden, ist schon nicht mehr ganz so einfach. Vor allem, wenn man's noch gar nicht gelesen hat. An der Universität Wien wird seit vielen Jahren eine Datenbank betrieben, die seit zwei Jahren auch im Internet verfügbar ist und alle Theaterinszenierungen in Österreich auflistet. Daneben ist aber auch ein Bereich "Literatur im Volltext" eingerichtet worden. Beispielhaft ist das Gesamtwerk von William Shakespeare aufgenommen worden. Die Rohdaten kommen aus dem Projekt Gutenberg. Die Suche nach: .....To be, or not to be- & führt nun genau an die richtige Stelle. Probieren Sie es aus; die Adresse ist: http://www.univie.ac.at/theadok
Und? Was hat Hamlet jetzt mit der Wirtschaftsförderung im Burgenland zu tun??
Nun ja: Die technische Lösung hinter dieser enorm schnellen Suche im Volltext des Gesamtwerkes von Shakespeare wird durch ein spezielles Datenbanksystem (BASIS) gewährleistet.
Die Anwendungen rund um diese Technologie werden von einem burgenländischen Unternehmen, der LIS Reinisch OEG entwickelt.
Kunden wie die AVL in Graz, die Veitsch Radex AG in Leoben aber auch die österr. POST AG zählen zu den Kunden der LIS Reinisch OEG. Natürlich nicht, um "die Stelle" im Hamlet zu finden, sondern um professionell in Forschungs- Patentdatenbanken oder in der internen Dokumentenverwaltung nach "Zitaten" zu suchen.
Seit Ende 1998 wird an einem vielversprechenden EUREKA Projekt gearbeitet.
Der Titel: Legal Information Systems / Multimedia, Projektnummer E!1979.
Ziel des Projektes war es, öffentliche Datenbanken multimedial aufzubereiten
und leichter (und attraktiver) einer breiten Öffentlichkeit zugänglich zu
machen. Als Beispiel wurde eine recht trockene Materie aufgegriffen. Rechtstexte
im Internet. Neben den allgemein geforderten vollständigen Inhalten, wie
(farbgetreue) Bilder und Anlagen, wurde ein hohes Augenmerk auf extrem schelle
Suche und auf intuitive Navigation gelegt. 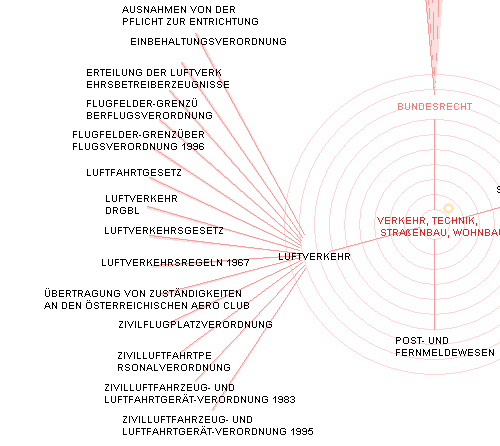
Bei der Diskussion um Inhalte und Oberflächen scheiden sich üblicherweise die Geister, aber:
Darf die Navigation in Gesetzestexten nicht auch Spaß machen?
Sollte es dem internetverwöhnten Normunterworfenen (wie wir offiziell genannt werden) nicht erlaubt sein, sich intuitiv durch den Gesetzesdschungel zu navigieren, anstatt mit unverständlichen, nur dem juristischen Insider bekannten (zugegebenerweise exakten) Zitierweisen zum Ziel zu gelangen?
Diese graphische Navigation ist letztendlich nur ein Hilfsmittel, um die enormen Datenmengen und Informationen gut portioniert vorgesetzt zu bekommen.
Die Abbildung links zeigt den graphischen Navigator CoNav.
Der sogenannte Power-User wir zusätzlich seine Suche mit komplexen Befehlen abschicken.
Ein weiterer Schwerpunkt des Projektes liegt in der morphologische Aufbereitung der Texte.
| ORIGINALWORT | ERMITTELTE ZERLEGUNG |
|---|---|
| Burgenländische | burgenländisch burgenlaendisch burgenlaendische burgenländische |
| Wirtschaftsförderung | wirtschaft förderung foerderung wirtschaftsfoerderung wirtschaftsförderung |
Nur mit aufbereiteten Texten kann auch nach einer fixen Struktur (mittels Thesaurus) navigiert werden. Der Einsatz von Thesauri erlebt durch die immer größer werdende Datenflut, aber auch durch die immer ungenauere Qualifizierung von Dokumenten eine Wiedergeburt.
Früher wurden Dokumente mühevoll "beschlagwortet". Dazu mußte man zum einen wissen, was in dem Dokument drinnen steckt, zum Anderen mußte man aber auch ahnen, wie ein Dokument später gesucht werden will.
In Zeiten von Altavista-Index und Yahoo macht "man" sich darüber nicht gerne mehr Gedanken.
In High-End Datenbanken hat sich aber an der Problematik durch die Einführung des Internets nichts geändert. Die Suche muß rasch zum exakten Ergebnis führen, ohne auf 100.000 Treffer zu stoßen.
 Auch die statistische Analyse von Dokumenten
erfordert (zumindest bei deutschsprachigen Dokumenten) eine
Aufbereitung der Rohdaten. Das Research Center Seibersdorf hat
mit dem Produkt BibTechMon ein interessantes Werkzug geschaffen, um aus großen
Dokumentenmengen Tendenzen und Inhaltliche Schwerpunktsänderungen feststellen zu
können. Aus der Häufigkeit des Auftretens bestimmter Worte in der Nähe zu
anderen Wörtern wird ein Netzwerk errechnet und visualisiert. Das beispielhafte
Ergebnis eines CoWord Maps ist hier
auszugsweise abgebildet.
Auch die statistische Analyse von Dokumenten
erfordert (zumindest bei deutschsprachigen Dokumenten) eine
Aufbereitung der Rohdaten. Das Research Center Seibersdorf hat
mit dem Produkt BibTechMon ein interessantes Werkzug geschaffen, um aus großen
Dokumentenmengen Tendenzen und Inhaltliche Schwerpunktsänderungen feststellen zu
können. Aus der Häufigkeit des Auftretens bestimmter Worte in der Nähe zu
anderen Wörtern wird ein Netzwerk errechnet und visualisiert. Das beispielhafte
Ergebnis eines CoWord Maps ist hier
auszugsweise abgebildet.
Eine Häufung von (inhaltlich) ähnlichen Begriffen scheint sich im Bereich "Antragstellung, Berechtigung, Schein" zu bilden. Kein Wunder, handelt es sich hier ja um die Daten aus dem österr. Luftrecht.
Das EUREKA Projekt wurde mit Projektpartnern aus 5 europäischen Ländern durchgeführt. Die Finanzierung erfolgte in den jeweiligen Ländern ausschließlich aus Eigenmittel. Seitens der WIBAG wurde eine Förderzusage gemacht.
Wenn Sie mehr zu diesem Projekt wissen wollen, besuchen Sie die Projekthomepage unter:
www.lis-oeg.com
Fragen zum Projekt richten Sie an:
LIS Luftfahrt Informatik Service Reinisch oeg
7441 Steinbach 49
Tel. 02616 4102
Fax. 02616 4103
Mail: reinisch@lis-oeg.com
Home: www.lis-oeg.com
Fragen zu weiteren Eureka Projekten richten Sie an:
BIT, Frau Michelle Killer
killer@bit.ac.at
Für Fragen zum BibTechMon wenden Sie sich direkt an:
D.I. Dr. Clemens Widhalm
Austrian Research Center Seibersdorf
clemens.widhalm@arcs.ac.at
Fragen zum ABC-MorphServer richten Sie an:
ABC System GmbH Niederlassung Österreich
Mail: reinisch@abc-system.com
Home: www.abc-system.com